
Google's Deep-Mind creates revolutionary "Neural Turing Machine"
 Google, the famous tech company that spreads its tentacles in every field that it sets sight on, recently took research on artificial intelligence to the next level. The achievement is based on the ability to combine neural networks with the computational resources of a computer. It is a well-known fact that no matter how accurate and powerful neural networks are, the computational resources needed to perform larger tasks grow with extremely high rates; this is the issue that Alex Graves, Greg Wayne and Ivo Danihelka , scientists in Deep-Mind Technologies (a Google-owned and London-based company) successfully overcame by building a “Neural Turing Machine”, a prototype computer/device/system which learns how to use working memory on its own and perform tasks such as copying, sorting and recalling information.
Google, the famous tech company that spreads its tentacles in every field that it sets sight on, recently took research on artificial intelligence to the next level. The achievement is based on the ability to combine neural networks with the computational resources of a computer. It is a well-known fact that no matter how accurate and powerful neural networks are, the computational resources needed to perform larger tasks grow with extremely high rates; this is the issue that Alex Graves, Greg Wayne and Ivo Danihelka , scientists in Deep-Mind Technologies (a Google-owned and London-based company) successfully overcame by building a “Neural Turing Machine”, a prototype computer/device/system which learns how to use working memory on its own and perform tasks such as copying, sorting and recalling information.
Description of the Neural Turing Machine
First of all, the main use of Neural Networks is pattern recognition. Pattern recognition is a highly useful branch of artificial intelligence, which tries to resemble the way our brain interprets figures and shapes and categorizes them, in order to quickly identify them. Neural Networks, correspondingly, is a branch that belongs to an important field of modern computer science called Machine Learning. There are several “types” of neural networks, which have only a few differences between them (found mainly in their structures); NTM uses Recurrent Neural Networks (RNNs), which have an advantage over other machine learning methods due to their ability to manipulate big sets of data over extended periods of time (RNNs are neural networks the neurons of which send feedback signals to each other). After implementing RNNs in their machine, scientists in Deep-Mind added a feature that extended the machine’s capabilities; and that is a “large addressable memory”. In simple words, NTM can manipulate temporarily (“short-term”) information and include all capabilities of conventional recurrent neural networks. This architecture is differentiable end-to-end (i.e. the non-linear activation functions throughout the network are differentiable) thus gradient descent can be used to train the RNN (gradient descent in RNNs is an optimization algorithm that is used to minimize total error by modifying weights between connections in proportion to the derivatives of the error, with respect to each weight).
Why was it named like that?
Alan Turing was a British mathematician most known for his research on computer science. He invented the hypothetical Turing Machine, a device with the purpose of reading symbols on a strip of tape according to a set of rules and consequently performing operations. The essence of a Turing Machine was created to explain the basic mechanism behind a computing machine, rather than to physically construct it.
The Neural Turing Machine, as it combines the processing capabilities of a digital computer and implements a class of Neural Networks, is an ideal naming scheme for this machine.
Examples and results of the NTM
In the experiments that were conducted with the NTM, the results were exceptionally satisfying.
“Our experiments demonstrate that it is capable of learning simple algorithms from example data and of using these algorithms to generalise well outside its training regime.”
You can find the full article with all the information and details here.
For the experiments, three different architectures were compared: 1) NTM with a feedforward controller, 2) NTM with an LSTM (Long short term memory) controller and 3) a standard LSTM network. (LSTM is recurrent neural network structure that differs from and supersedes other types of RNNs when it comes to classifying, processing and predicting time series when there are very long time lags of unknown size between important events).
The tasks that were put to test with Deep-Mind’s NTM were: copy, repeat copy, associative recall, dynamic N-Grams and priority sort. Note that all figures were taken from the aforementioned original paper.
Copy
In this task the NTM is tested for its ability to store and recall a long sequence of arbitrary information. The input sequence consisted of eight bit random binary vectors followed by a delimiter flag, and the sequence lengths were randomized between 1 and 20.
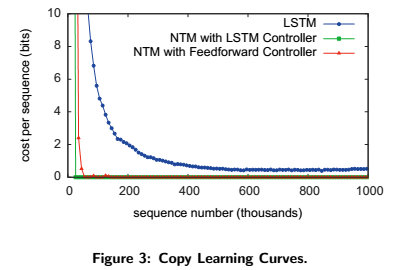
Below is the figure that displays the cost per sequence (error) to sequence number curves. NTM (with either controller) learns faster than LSTM alone and converges to a lower cost.
The figures below demonstrate the performance of the networks to generalize to longer sequences than what they were trained for. Again, NTM (top) does better than LSTM (bottom).

Repeat Copy
This test is similar to the previous one, only that now the copied sequence is output a specified number of times and then emit an end-of-sequence marker.
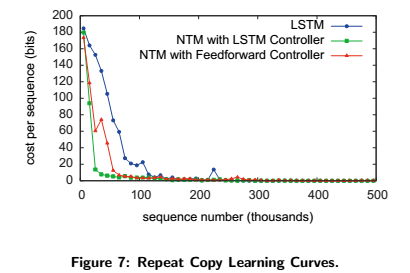
Below is the figure displaying the cost per sequence (error) to sequence number curves. Even though NTM (with either controller) learns quicker than LSTM, they both converge to the same cost in the end.
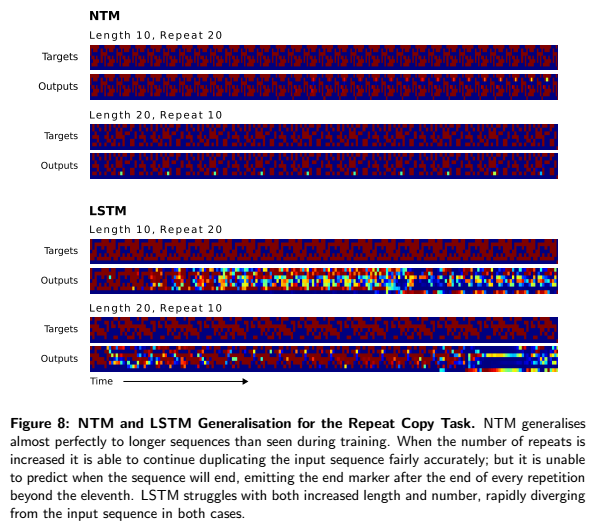
The figure below demonstrates how well NTM and LSTM perform to the generalization tasks (like in the previous test). NTM does a lot better than LSTM.
Associative Recall
In this test, the ability of the network to organize data which includes items that point to one another (essentially forming a pattern, you could say).
The figure below displays the cost per sequence (error) to sequence number curves. Once more, NTM is more efficient in this task than LSTM, since it learns a lot faster than the latter and reaches zero cost after about 30,000 episodes, whereas LSTM doesn’t reach zero cost even after a million episodes.
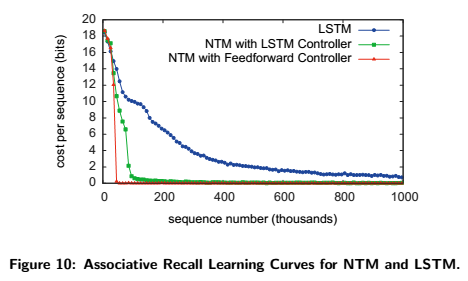
The figure below demonstrates how well the networks generalize this task; NTM does great, but LSTM screws up big time.
 Dynamic N-Grams
Dynamic N-Grams
With this test, the researchers tried to examine whether (and at what rate) NTM could adapt to new predictive distributions. Or, to be precise, if the network could emulate an N-Gram model by keeping count of transition statistics and allowing its memory to act as a re-writable table.
The learning curves of the networks are represented below. Note that although NTM is better than LSTM (i.e. learns faster and converges to a lower cost), it never really reaches the optimum cost.
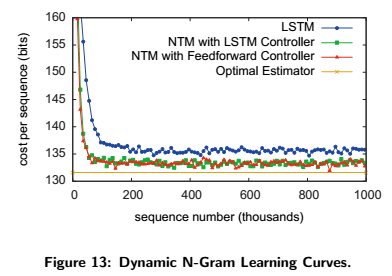
And here are the results of the task:
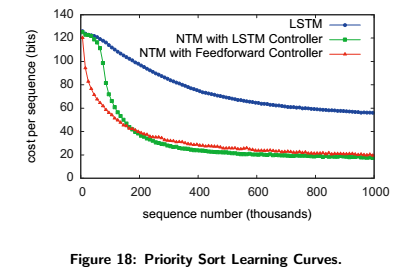
 Priority Sort
Priority Sort
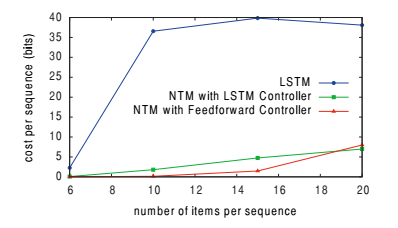
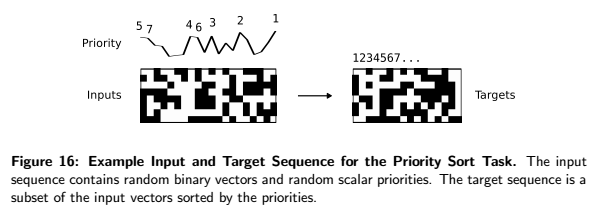
This is the last experiment that was conducted. It measures the network’s performance when it comes to sorting data with items that have “ratings” (each item has a rating randomly picked between values of [-1, 1]). The network sorts the items according to their ratings. The visual representation of the task below will help you better understand how it works:
The figure below displays the cost per sequence (error) to sequence number curves. You can guess that NTM does significantly better than LSTM again:
Conclusion
As you can see, this breakthrough in modern machine learning is very promising. With all the work that’s been put in this area the recent years, we can expect great things to come in the near future- and not only from big tech companies and scientists, but from anyone who can add his own piece of research in the sea of technology.